Curated Resource ( ? )
When Should We Trust AI? Magic-8-Ball Thinking
Curated:
20/08/2024 from
www.nngroup.com/articles/ai-magic-8-ball/
my notes ( ? )
Generative artificial intelligence (genAI) has practical applications for UX practitioners. It can accelerate research planning, crossfunctional communication, ideation, and other tasks. GenAI has also trivialized labor-intensive activities such as audio transcription. However, a dark cloud lurks over every use and implementation of genAI — can we trust it?
In This Article:
- Hallucinations
- What Is Magic-8-Ball Thinking?
- How Can Magic-8-Ball Thinking Be Avoided?
- Should Designers Consider Magic-8-Ball Thinking When Building AI Features?
- References
Hallucinations
GenAI tools consistently make mistakes when performing even simple tasks; the consequences of these mistakes range from benign to disastrous. According to a study by Varun Magesh and colleagues at Stanford, AI-driven legal tools report inaccurate and false information between 17% and 33% of the time. According to a Salesforce genAI dashboard, inaccuracy rates of leading chat tools range between 13.5% and 19% in the best cases. Mistakes like these, originating from genAI outputs, are often termed “hallucinations.”
Some notable instances of genAI hallucinations include:
- Google’s AI Overviews feature recommended that people make pizza with a quarter cup of nontoxic glue as an ingredient to prevent cheese from sliding off the pizza after cooking.
- The National Eating Disorders Association implemented a chatbot recommending disordered eating habits to its users.
- According to Alex Cranz from The Verge, Meta’s AI image-generation tool continuously generated pictures of masculine-looking people with beards when asked to create pictures of the author, who identifies as a woman.
Mistakes due to hallucinations stem from how large language models (LLMs, the technology behind most genAI tools) work. LLMs are prediction engines built as probabilistic models. They work by looking at the words that came before and selecting the most likely word to come next, based on the data they’ve seen before.
For example, if I were to ask you to finish the following sentence, you could probably do so quite well:
“The quick brown fox jumps over the lazy …”
If you speak English, you most likely would answer with the word “dog,” as it is the most likely word to come at the end of this sentence, which famously uses all the letters in the English alphabet. However, there is a small chance that the word I expected at the end of this sentence was “cat,” not “dog.”
Since LLMs are exposed to training data from all corners of the internet (copyrighted or otherwise), they learn associations between syllables from extensive examples of sentences people have written across human history, leading to their impressive ability to respond flexibly to requests from users. However, these models have no built-in understanding of truth, of the world, or even of the meanings of the words they generate; instead, they are built to produce smooth collections of words, with little incentive to communicate or verify the accuracy of their prediction.
The term “hallucination” is often used to describe the mistakes made by LLMs, but it may be more precise to describe these mistakes as “creative gap-filling” or “confabulation,” as Benj Edwards suggests in Ars Technica.
Clearly, AI models' inability to measure truth is a problem. Tech executives and developers alike have little confidence that the AI-hallucination problem will be solved soon. While these models are extremely powerful, their probabilistic, generative, and predictive structure makes them susceptible to hallucinations. Although hallucination rates have decreased as improved models have been released, any proposed solutions to the hallucination problem have fallen short.
As such, it falls to the users of genAI products to evaluate and judge the accuracy and validity of each output, lest users act on a piece of confabulated information that “looked like the right answer.” Depending on the context of the use, the consequences of a hallucination might be inconsequential or impactful. When humans uncritically accept AI-generated information, that’s magic-8-ball thinking.
What Is Magic-8-Ball Thinking?
In her recent talk at the Rosenfeld Advancing Research Conference, Savina Hawkins, an ex-Meta strategic UX researcher and founder of Altis, an AI-driven customer-insights product, coined the term “magic-8-ball thinking” to refer to taking a genAI output at face value, trusting it and acting upon it.
Magic 8-ball thinking is the tendency to accept AI-generated insights uncritically, treating them as truth rather than probabilistic output based on training data and model weights.
A magic 8-ball is a plastic ball styled like an oversized cue ball, containing a floating 20-sided die with different statements on each side, often used to seek advice or predict fortunes.
Simply put, magic 8-ball thinking occurs when users stop verifying answers they receive from genAI products and trust the answer instead.
Users of genAI products are most likely to engage in magic-8-ball thinking when:
- Using AI for tasks or topics outside their personal expertise (and ability to recognize the truth)
- Failing to actively engage with their own intellect or capabilities during interactions with genAI systems
- Assuming a higher degree of capability of genAI than is realistic
- Becoming complacent after receiving good, realistic answers from genAI products
Users tend to have inflated trust in AI tools for myriad reasons, the ELIZA effect among them. A recent diary study conducted by NN/g confirms that users have high levels of trust in AI tools
How Can Magic-8-Ball Thinking Be Avoided?
Generative AI tools are great for reducing tedium and filling skill gaps, but be careful about overextending your trust in these tools or overestimating their abilities. Users should interact with genAI only to the extent they can check the AI’s outputs using their own knowledge and skills.
How can users check results for accuracy? It’s a tough question. Use only information you can verify or recognize to be true. Stay within your broad umbrella of expertise. If you lean on genAI too much or feel unable to check the validity of a given response, then you might be veering into magic-8-ball thinking — you might be trusting the black box a bit too much.
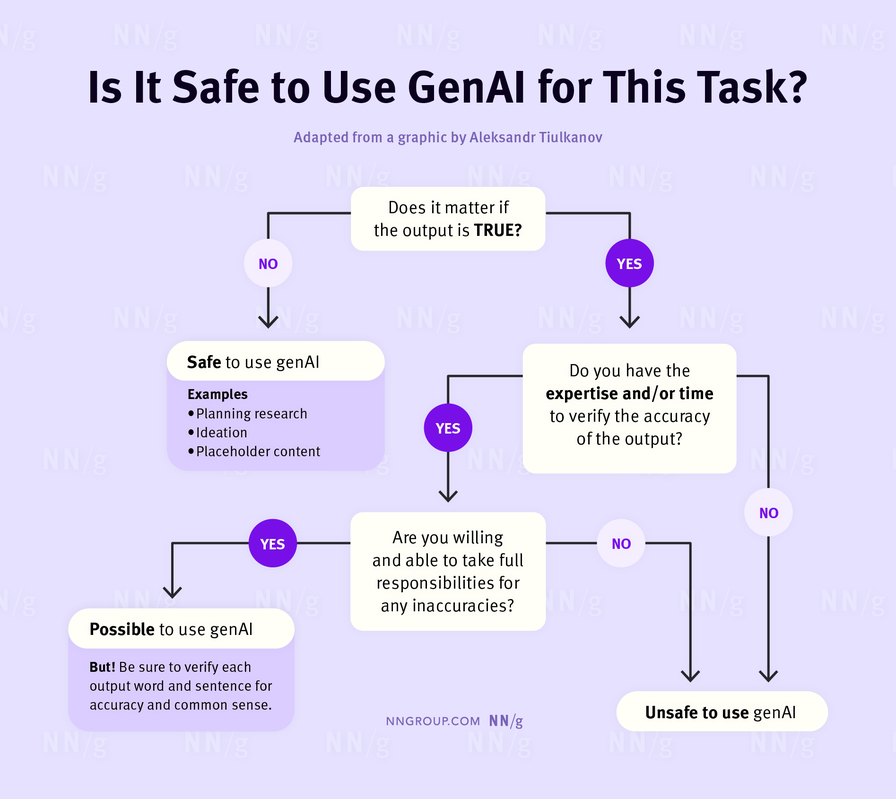
However, there are situations in which your level of trust in genAI is less important. You do not need to check an LLM’s output if it does not matter if the output is truthful. Examples include generating “text that looks right,” such as marketing or UX copy, placeholder text, or initial drafts of documents. Lennart Meincke, Ethan Mollick, and Christian Terwiesch have demonstrated genAI’s useful role in ideation, leveraging LLMs’ ability to output massive lists of ideas, helpfully constrained by clever prompting. These applications can avoid the magic 8-ball effect since their utility does not hinge on factual accuracy.
Users may use an LLM for important tasks that require veracity if they have the expertise, time, and capacity to check and verify outputs from an LLM; users must also be in the position to take full responsibility for any inaccuracies. Examples include:
- An expert researcher generates interview questions for an upcoming usability study; the researcher can verify outputs and revise or edit them to correct errors.
- A quantitative UX researcher uses an LLM to write code for statistical analysis; the researcher may not know the exact syntax but can catch inevitable errors in the output code and also recognize whether the AI has chosen the right statistical tests.
Do not use AI as a complete replacement for your work. Instead, treat it as an assistant who may be able to speed things up and take care of busy work, but whose output you always need to check.
Your expertise is still valuable because these models make mistakes all the time. UX professionals are responsible for making good qualitative judgments and have developed those skills. If you’re already an expert, then you can use AI much more effectively and check its outputs for errors efficiently and competently.
The requirement to verify anything an AI tool creates limits its usefulness, because it increases the time and effort to use these tools. It also raises the bar for what useful AI help looks like; the benefits of any genAI have to be high to justify the effort invested in its function.
When adopting any tool for professional use, you must ask yourself: Does this save time? Is this worth it? If you were required to look over every email sent on your behalf by a hypothetical executive assistant, you might be better off writing that email yourself. The same goes for AI.
Here are some examples of situations to practice avoiding magic-8-ball thinking:
- When conducting desk research with genAI tools, request sources, references, or URLs alongside your searches. Click through and verify the sources provided, since genAI tools will often cite sources unrelated to a topic.
- GenAI tools can accelerate qualitative data analysis; avoid magic-8-ball thinking by asking the tool to link qualitative insights back to your original data.
- Programming and quantitative analysis tasks can be vastly accelerated with genAI, but you need to verify any code, statistics, or visualization choices that are made by a genAI tool.
- Never directly send, publish, or share a piece of writing generated by a genAI tool without reviewing it first.
Should Designers Consider Magic-8-Ball Thinking When Building AI Features?
Intentionally or unintentionally exposing users to AI hallucinations introduces the possibility that they feel disappointed and confused. In the worst situations, those feelings could metastasize into lower engagement or abandonment of the entire product. While AI hallucination rates are still high enough to be an ongoing issue, professionals designing for AI integrations can add features to help users check or trace where outputs are coming from.
When implementing a genAI feature into a product, conduct user research to identify the likelihood that users will engage with magic-8-ball thinking in the context of your implementation. If your product’s implementation of AI includes generating text-based content, consider adding features to prevent magic-8-ball thinking.
Examples of such features include:
- Annotating genAI outputs with references to information sources used in generating the response (e.g., in the form of in-line citations, information cards at the top or bottom of the output, or See sources button)
- Despite reprehensible behavior regarding intellectual property theft, Perplexity has a good demonstration of annotating responses with sources in its core product.
- Dovetail, a qualitative research platform, summarizes transcripts from video recordings using genAI; to improve users’ ability to check its output, Dovetail provides links to timestamped sections of each recording inside the summary.
- Allowing users to conduct a traditional web or literature search inside the product, within the context of the genAI response
- Google’s Gemini chat product includes a Double check response button, which evaluates the genAI’s output and provides dropdown options to expand separate Google searches for different components of Gemini’s output.
References
Tiulkanov, Aleksandr. 2023. A simple algorithm to decide whether to use ChatGPT, based on my recent article. LinkedIn. From https://www.linkedin.com/posts/tyulkanov_a-simple-algorithm-to-decide-whether-to-use-activity-7021766139605078016-x8Q9/ Anon. Neda on Instagram. Retrieved June 3, 2024 from https://www.instagram.com/p/Cs4BiC9AhDe/
Alex H. Cranz. 2024. We have to stop ignoring AI’s hallucination problem. May 2024. The Verge. Retrieved June 3, 2024, from https://www.theverge.com/2024/5/15/24154808/ai-chatgpt-google-gemini-microsoft-copilot-hallucination-wrong
Benj Edwards. April 2023. Why AI chatbots are the ultimate BS machines—and how people hope to fix them. Ars Technica. Retrieved August 2, 2024 from https://arstechnica.com/information-technology/2023/04/why-ai-chatbots-are-the-ultimate-bs-machines-and-how-people-hope-to-fix-them/
Nico Grant. 2024. Google rolls back the AI search feature after Flubs and Flaws. June 2024. The New York Times. Retrieved June 3, 2024 from https://www.nytimes.com/2024/06/01/technology/google-ai-overviews-rollback.html
Hawkins, S. March 2024. Harnessing AI in UXR: Practical Strategies for Positive Impact. In *Advancing Research 2024*. Rosenfeld Media. Retrieved from https://rosenfeldmedia.com/advancing-research/2024/sessions/harnessing-ai-in-uxr-practical-strategies-for-positive-impact/
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. October 2023. Halueval: A large-scale hallucination evaluation benchmark for large language models.. Retrieved June 21, 2024, from https://arxiv.org/abs/2305.11747
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, and Daniel E. Ho. 2024. Hallucination-free? Assessing the reliability of leading AI Legal Research Tools. (May 2024). Retrieved June 21, 2024, from https://arxiv.org/abs/2405.20362
Dhruve Mehhrotra, Time Marchman, June 2024. Perplexity Is a Bullshit Machine. Wired. Retreived August 2, 2023 from https://www.wired.com/story/perplexity-is-a-bullshit-machine/
Lennart Meincke, Ethan Mollick, and Christrian Terwiesch, Februrary 2024. Prompting Diverse Ideas: Increasing AI Idea Variance. The Wharton School Research Paper. From https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4708466
Nilay Patel, May 2024. Google CEO Sundar Pichai on AI, search, and the future of the internet. The Verge. Retrieved August 2, 2024 from https://www.theverge.com/24158374/google-ceo-sundar-pichai-ai-search-gemini-future-of-the-internet-web-openai-decoder-interview
Salesforce AI Research. Generative AI benchmark for CRM. Retrieved June 21, 2024, from https://www.salesforceairesearch.com/crm-benchmark
Wikipedia. Hallucination (artificial intelligence). Retrieved August 2, 2024 from https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)#Mitigation_methods
Read the Full Post
The above notes were curated from the full post www.nngroup.com/articles/ai-magic-8-ball/.Related reading
More Stuff I Like
More Stuff tagged llm , artificial intelligence , genai , ai , generative artificial intelligence
See also: AI, chatGPT, LLM