Curated Resource ( ? )
Specification gaming: the flip side of AI ingenuity
Curated:
26/06/2023 from
deepmindsafetyresearch.medium.com/specification-gaming-the-flip-side-of-ai-ingenuity-c85bdb0deeb4
my notes ( ? )
"Specification gaming: a behaviour that satisfies the literal specification of an objective without achieving the intended outcome" - the earliest popular example would be the Sorcerer's Apprentice, followed by the paperclipmaker which destroys the universe, but the Midas legend probably came first.
The authors "have collected around 60 examples " of specification gaming by artificial agents, and "review possible causes ... share examples ... argue for further work on principled approaches to overcoming specification problems."
The problem is considered from 2 perspectives:
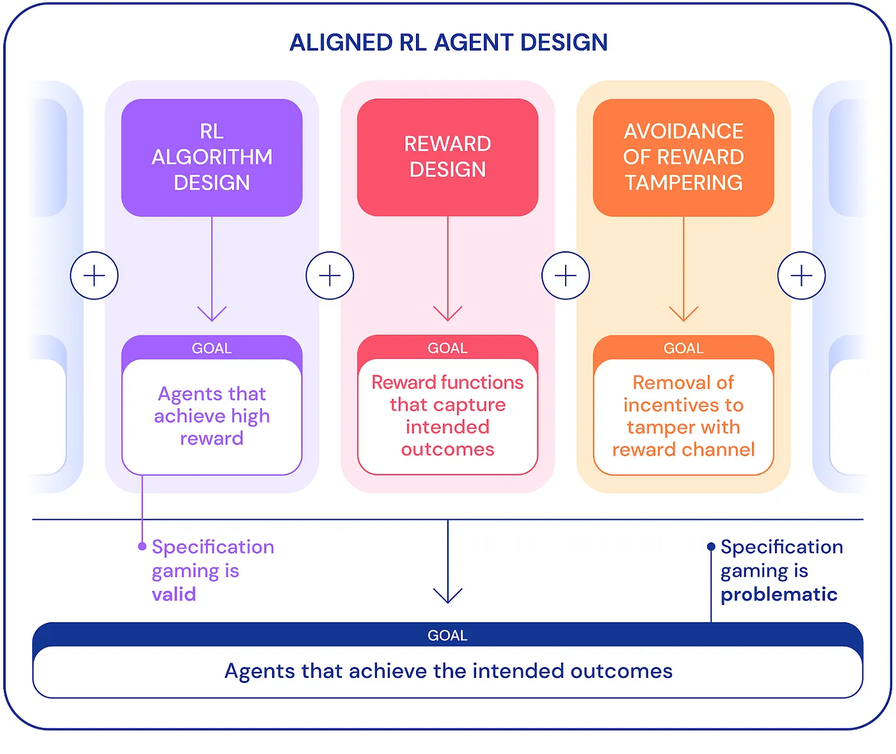
1) when "developing reinforcement learning (RL) algorithms, the goal is to build agents that learn to achieve the given objective... [if] the agent solves the task by exploiting a loophole is unimportant ... [so] specification gaming is a good sign... demonstrate the ingenuity and power of algorithms"
2) On the other hand "the same ingenuity can pose an issue" when trying to build " aligned agents that achieve the intended outcome in the world... [caused by] "misspecification of the intended task.
As LLMs get better, they'll get better at finding unintended methods to achieve goals, so knowing how to correctly task an LLM will become increasingly difficult and important. This "task specification includes not only reward design, but also the choice of training environment and auxiliary rewards."
Challenges to overcome:
- accurately capture the user's concept of a given task in a reward function
- "avoid mistakes in our implicit assumptions ...
- design agents that correct mistaken assumptions instead of gaming them
- ... avoid reward tampering
Several things to keep in mind:
- "Reward shaping makes it easier to learn some objectives by giving the agent some rewards on the way to solving a task". Rewards should be "potential-based"
- Teach the reward function with human feedback, as it's "often easier to evaluate whether an outcome has been achieved than to specify it explicitly", although this risks not teaching the designer's true requirements.
- simulator bugs: "a failure of abstraction that can be exploited"
- "as tasks grow too complex ... [risk] introduce incorrect assumptions during specification design.
- " reward tampering: ... agent deployed in the real world ... manipulates these representations of the objective" including the user's objectives and even an AI "hijacking the computer on which it runs, manually setting its reward signal"
Read the Full Post
The above notes were curated from the full post deepmindsafetyresearch.medium.com/specification-gaming-the-flip-side-of-ai-ingenuity-c85bdb0deeb4.Related reading
More Stuff I Like
More Stuff tagged llm , specification gaming , alignment , ai
See also: Digital Transformation , Innovation Strategy , Science&Technology , Large language models